Always On-Air ®
First Hybrid Driven IP Workflow Platform
Media Center MC365 is Platform based on many advance technologies.
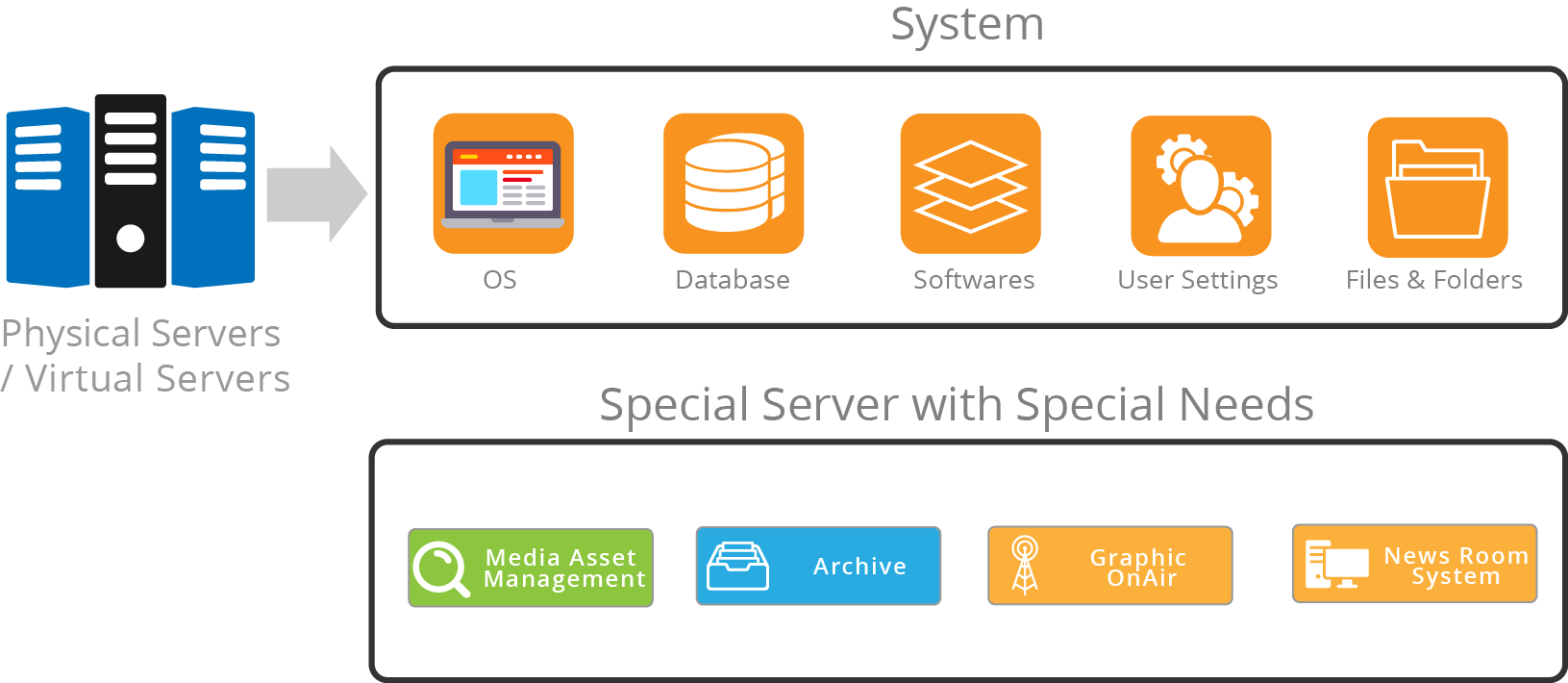
It consists of Scale-out Hybrid (physical, virtual, Cloud) as an intelligent Media or Storage node. The MC365 designed and optimized for popular Media and broadcasting workflows components such as Media Asset Management (MAM) / Digital Asset Management (DAM), News Room, Transcoding playout, ingest, graphics on air and many more. Compatible with Windows® or Mac OS®.
MC365 combines the power of high-performance SAN for databases and file share NAS storage for media files, Integrated high-performance Xeon class Server(s) and high-speed network(s) in a fully scalable and integrated hardware and software solution.
MC365 to boost user workflows efficiency, productivity, simplicity.
Cloud Connect to Microsoft Azure and AWS extend its capabilities as a hybrid
Unique file system technology enables exceptionally high bandwidth across all workloads.
Simple & cost-effective to deploy, manage & scale Integrates with all Media Asset management.Support for hardware-driven IP workflows using NewTek NDI®Apple® Final Cut Pro®, Avid® Media Composer® and Adobe® Premiere® Pro.
ETERE, VIZRT, Grass Valley, Ross video, Avid, Imagine communications, Harmonics, Dalet, Brainstorm, APTN
Every node can accommodate any combination of Enterprise SAS, SSD flash, cloud storage,
Cloud connect allows provisioning of Microsoft Azure Hot & Cool Blob, Amazon S3, and Glacier as a different tier of storage and resource for MC365.
Media Center appliances are available in 3 different configurations: integrated, high-availability modular(HA), or scale out. An embedded hypervisor allows your workflows compontes such as MAM, Archive, transcoder and News run as virtual machines directly on the Media Center at no extra cost.
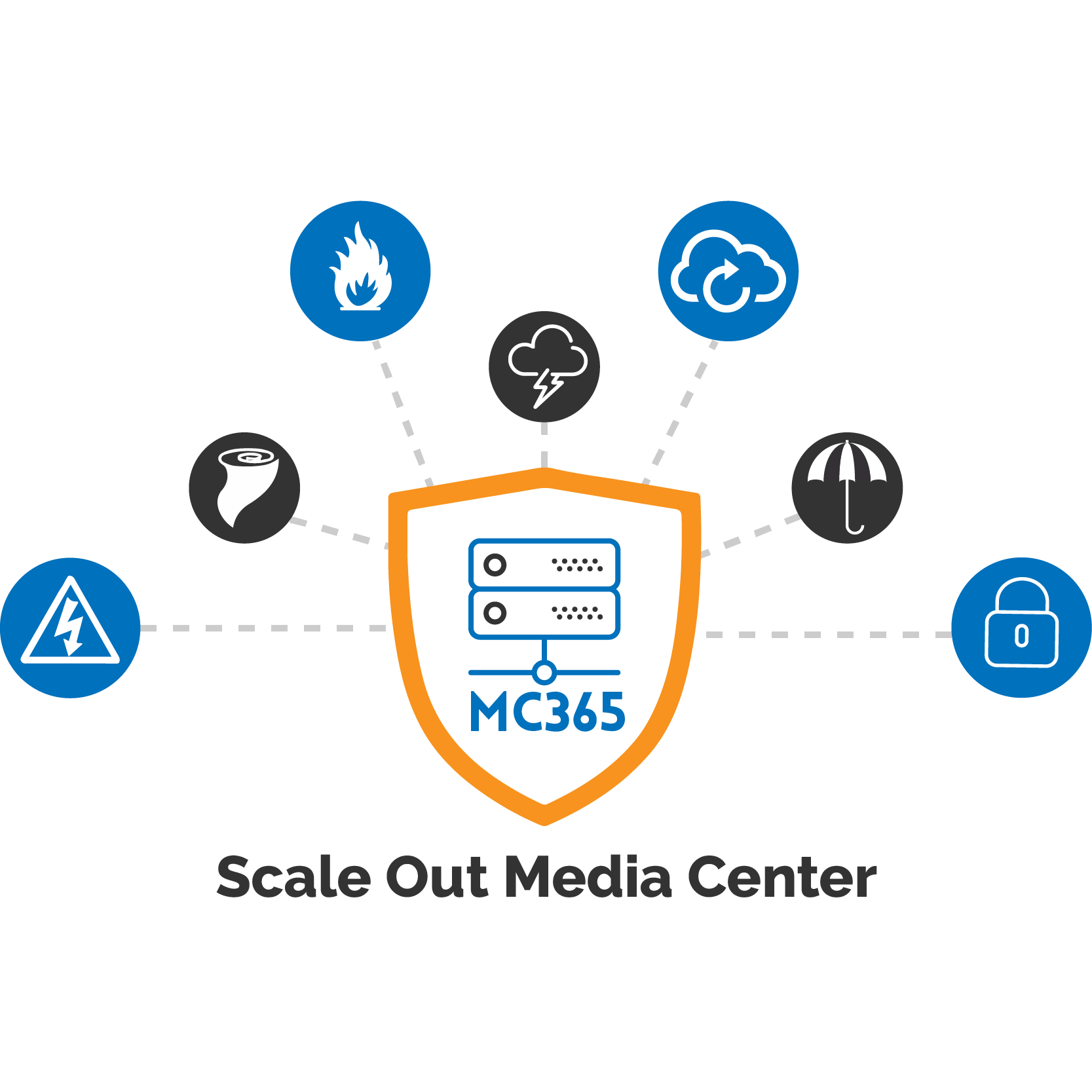
Always On-Air® Scale Out Media Center Platform for Enterprise Workflow
High Scalability
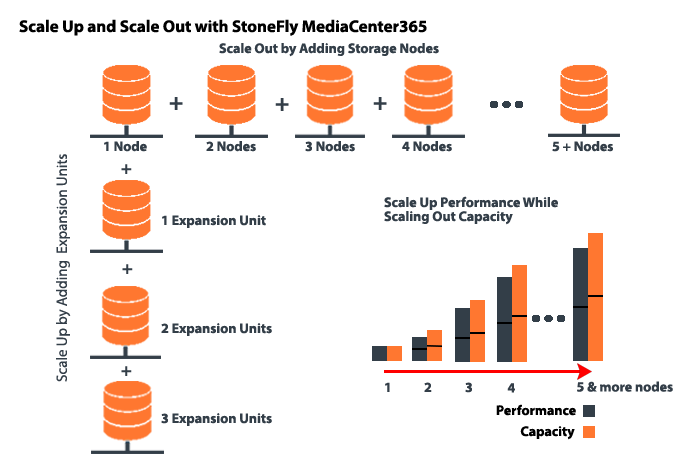
Media Center is based on a fully distributed scale-out architecture, Add nodes and elasticity increase performance, capacity and resources (storage, server, network) . As the system scales, bandwidth and capacity increase linearly.
Simple and Cost-Effective – Lowest cost of CapEx and OPex
Based on standard hardware components and cost-effective 1/10/40/100G Ethernet technology, Media Central has lower Capex and OPex.. Buy what you need and scale as your workflows grows. NO forklift upgrade.
Optimized for Media Workflows
Media Center works with dozens of leading media systems, including ETERE, VIZRT, Grass Valley, Ross video, Avid, Imaging communications, Harmonics, Dalet, Brainstorm, APTN. It also enables collaborative editing workflows with nonlinear editors, such as Apple® Final Cut Pro®, Avid® Media Composer® and Adobe® Premiere® Pro.
Reliability and Availability
Media Center systems have no single point of failure, and leverage features such as Clustering, dual active-active nodes with transparent failover, redundant data paths to protect against componet and node failures. No down time is required even for activities such as software and firmware upgrades or adding storage nodes.
Always On-Air™
MC365 ’s comprehensive redundant, clustering, fault-tolerant self-healing, fail-over architecture, and integrated disaster recovery (on-prem, remote and cloud) with a complete content replication provides Always on-Air®. On-Perm-Remote, Cloud, always up and running.
What can we manage:
Media Center Scale out
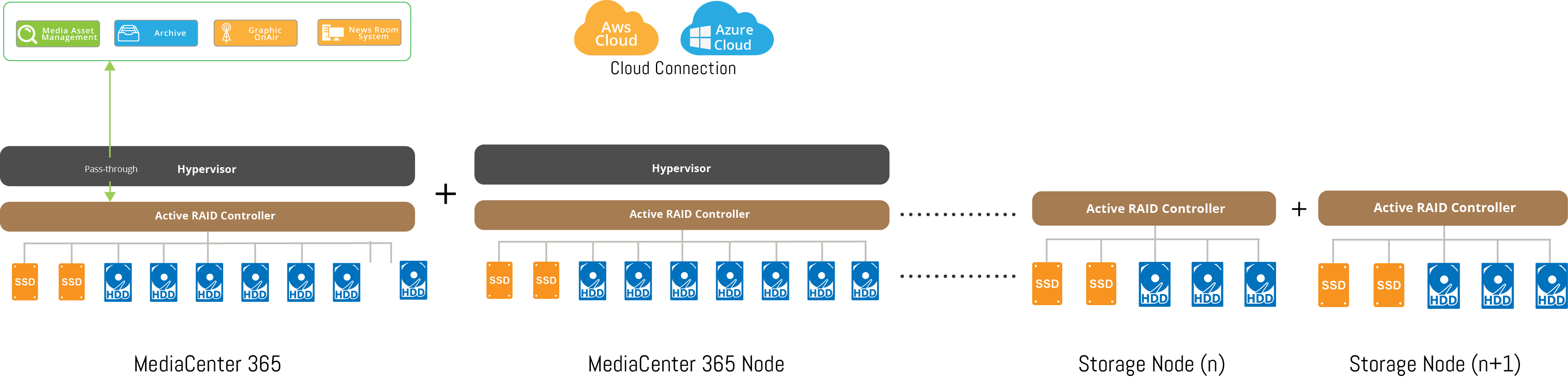
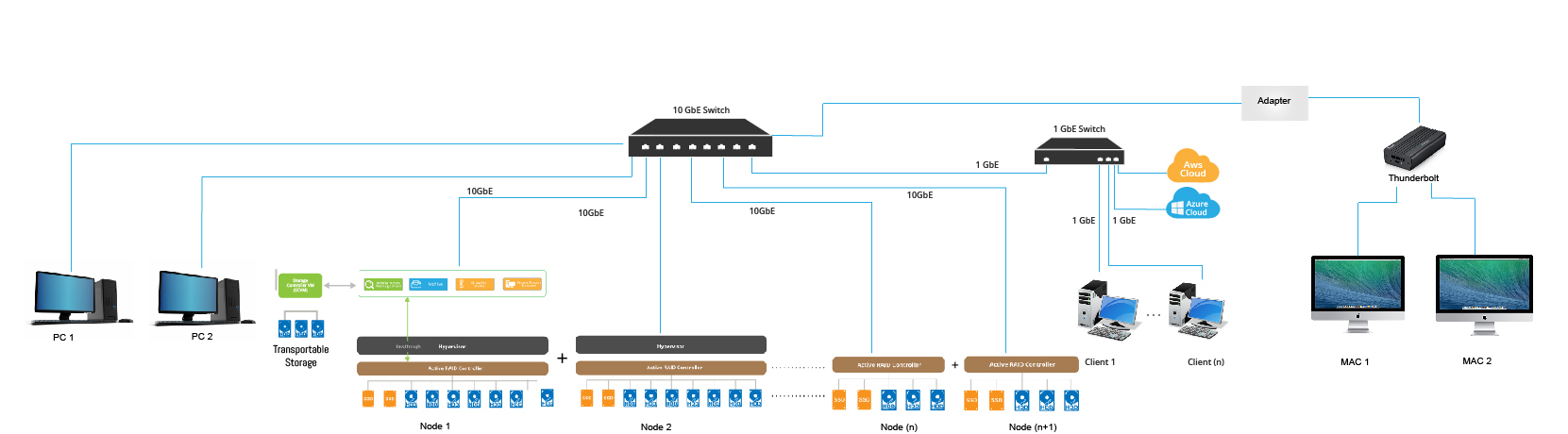
Manage nodes with just a single user interface. Each time a node is Scaled Out, it adds more capacity, more throughput, and more concurrency. Installation, management, and scaling is simple to achieve at any size.

Scale out High Availability, Performance workload, Capacity?
MC365 can Scale to theoretical unlimited petabytes all while handling thousands of clients and workflows. It functions as a distributed resource overlay, polling together Storage, CPU, memory, network resources as building blocks over TCP/IP, aggregating resources and managed as a single global Always On-Air® system.
Technical features of repository:
NO Metadata – NO MetaData Director, NO Centralize Database, any request can be handled by any node at any time by hashing the Read/Write request to calculate the file location across all the nodes. By automatically calculating the answer, Integrated Scale Out NAS avoid bottleneck and Metadata corruption and can handle a wide range of files size without affecting the performance and allowing for unlimited scalability.
In addition to No Metadata Model, Other performance Techniques employees are: Read ahead, Write behind, Async IO, Intelligent I/O, Aggregated Operations,
Distributed File System – A file system in which data is spread over different nodes where users can access the file without knowing the actual location of the file. User doesn’t experience the feel of remote access.
Stackable design allows for agile development and deployment for a new feature for customers to enjoy.
Standard file format XFS alongside Stonefly’s Scale out NAS operating system ensures full compatibility and guarantees customers access to the files with standard OS. NO Vendor dependency.
>Each Server client can access their files from any node. One a single IP for all the nodes. Exclusive access can be given to one or multiple clients to be serviced by one IP node.
NO or little Inter-Node traffic. NO need to high-speed interconnects and Network to purchase and maintain.
Performance Able to deliver when properly configured Can exceed aggregate read and write speed in most use cases with files sizes at full network bandwidth of up to 3GB/Sec per Node and aggregate as more node added.
Support of Hardware Raid and Erasure coding within or across Nodes for unlimited High availability and redundancy. Selectable redundancy failover from 1 to 5 disk per node.
Segments are partitions that files are placed for sharing between trusted storage pools.
volume is a logical collection of segments. Most of the management operations are performed on the volume such expansion.Volume can expand across nodes to create a single namespace.
Auto Re-balance allows a distributed volume with only one segment. For instance, we create 10 files on the volume through volume. Now all the files are residing on the same segment since there is only segment in the volume. On adding one more segment to the volume, we may have to re-balance the total number of files among the two segment. If a volume is expanded or shrunk.
Erasure coding (EC) is a method of data protection in which data is broken into fragments, expanded and encoded with redundant data pieces and stored across a set of different locations
Volume supported Distributed – Striped- Distributed Sync Mirrored – Distributed Mirrored – Distributed Striped Mirrored- Dispersed – Geo-Dispersed On-Perm-Clouds and Clouds-Clouds.
Distributed Volumes This type of volume spreads files across the segments in the volume across the nodes.
Dispersed volumes are based on erasure coding. This allows the recovery of the data stored on one or more Segments in case of failure. The number of segments s that can fail without losing data is configured by setting the redundancy count.
Dispersed volume requires less storage space when compared to a mirrored volume. It is equivalent to a mirrored pool of size two, but requires 1.5 TB instead of 2 TB to store 1 TB of data when the redundancy level is set to 2. In a dispersed volume, each segment stores some portions of data and parity or redundancy. The dispersed volume sustains the loss of data based on the redundancy level. Redundancy level of up 1 to 5 can be set in the dispersed configuration.
Distributed Dispersed volume there will be multiple sets of segments (sub-volumes) that stores data with erasure coding. All the files are distributed over these sets of erasure coded segments. In this scenario, even if a redundant number of segments is lost from every dispersed subvolume, there is no data loss.
Automated Tiering Great for stable workloads, cost saving where frequently used data fits on small, fast storage, such as SSDs and less frequently accessed or old data resides on a slower/cheaper/remote volume, node, cloud, such as spinning disks, Hot Blob, Cool Blob(Azure), S3, Glacier (amazon)
On a tiered volume, files are tracked according to the frequency of access. More accessed files tend to migrate to faster storage and less frequently used to slower storage. The behavior can be influenced with tuning parameters.
Self-heal If any of the segments in a replicated volume are down and users modify the files within the other segments, the automatic self-heal daemon will come into action as soon as the segment is up next time and the transactions occurred during the down time are synced accordingly.
Protocol support: CIFS, NFS the most popular used protocols.
POSIX – Portable Operating System Interface (POSIX) is the family of standards defined by the IEEE as a solution to the compatibility between Unix-variants in the form of an Application Programmable Interface (API).e data needs to be re-balanced among the various segment included in the volume.
Geo-replication – It provides back-ups of data for disaster recovery. Here comes the concept of master and slave volumes. So that if the master is down the whole of the data can be accessed via slave. This feature is used to sync data between geographically separated servers. Geo-replication can be done from or to On-perm to Public (Microsoft Azure, Amazon (AWS) Private Cloud and Cloud to cloud private or public.
Cloud Cache: Build in Flash Cache feature allows some volumes be used as a front-end cache for Public cloud storage such Microsoft Azure Blobs or S3 and Glacier from Amazon.
Snapshot Provides flexibility in data backup – The Snapshot is block bases which create a point in time backup delta from the only blocks that have changed from the last snapshot. Snapshot is read-only files that help in recovery and protection against ransomware.
Encryption Network encryption using TLS/SSL for authentication and authorization,
I/O encryption – encryption of the I/O connections between Clients and NA
Management encryption – encryption of the management connections within volumes. The node and volumes can be fully dispersed between On-Per and Clouds. Support for ASE-256 at rest and transit.
Optional Integrated Backup and Disaster Recovery
- Full recovery Recover an entire machine on the original host or on a different host. Includes quick rollback functionality to restore changed blocks only.
- Instant Recovery Quickly restores service to users by starting a server directly from a backup file on regular backup storage.
- Direct Restore to Microsoft Azure or Amazon Restore or migrate on-premises, Windows-based or Linux-based machines, physical servers, and endpoints directly into Microsoft Azure
- Instant File-Level Recovery Recover files from 19 common file systems used by Windows, Linux, BSD, Mac OS, Novell, Solaris, and Unix.
- 1-Click File and servers recovery portal Restore Guest files and servers with a single click through a web UI.
- Application-aware, image-based backups Create application-consistent, image-level server backups with advanced, application-aware processing (including transaction log truncation).
- Backup I/O control Allows you to set the maximum acceptable I/O latency level for production datastores to ensure that backup and replication activities do not impact storage availability to production workloads. Enterprise edition includes a global latency setting, and Enterprise Plus edition provides setting customization on a per datastore basis.
- Cloud Connect Backup Get your backups off site with fully integrated, fast and secure backup, and restore from the cloud.
- Built-in WAN Acceleration Get backups offsite up to 50x faster and save bandwidth
- Multiple storage access options Backup and replicate directly from SAN and NFS storage, through hypervisor I/O stack or over LAN.
- Replace your data center by migrating existing Windows and Linux physical servers into Virtual Machines hosted on the StoneFly Media Center.
- Quickly spin up new Virtual Machines on the StoneFly Media Center.
- Physical machines Support.
- Virtual Machines hosted on the StoneFly Media Center
- Global shared back-end object/block/image storage for OpenStack
- Create numerous delta-based snapshots to back up the iSCSI SAN volumes containing your VMs and storage. Then use mountable read-write snapshot volumes for recovery.
- Easy and flexible volume management and resource allocation with thin provisioning and space reclamation.
- Synchronously replicate (campus mirror) all of your servers and storage to a second on premises Media Center appliance for business continuity.
- Asynchronously replicate all of your servers and storage to the cloud or a StoneFly Media Center at a remote site for disaster recovery.
- Protect your data and increase system uptime with high-performance hardware RAID.
- Optimized storage efficiency with block level parallels data deduplication with high-performance index engine.
- Integrated SAN snapshot – Great for Ransomware isolation – Read only – Mountable as Read/Write
- Optional enterprise-level hardware-enabled block level AES 256 volume encryption.
- Scale out storage and servers across multiple Media Center nodes.
-
Microsoft Azure (page, Hot, cool Blob), AWs (S3, Glacier) and Private cloud.
- Tiered Storage – HOT, Cold On-Prem or On-Prem to the cloud
- Each Node Scale up to 5 PB and Scale out with unlimited capacity and number of nodes- HyperScale.
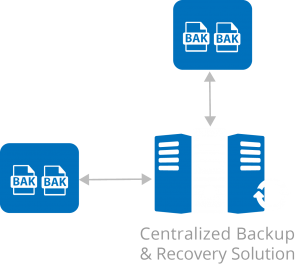
Centralized Backup & Recovery Solution
In addition to the Virtual Machines running directly on the Media Center appliance, the Media Center can back up any of your physical workstations, servers, and their attached storage devices. Bare-metal image backups of physical servers can be instantly recovered on the Media Center and run as Virtual Machines while you repair the physical server or workstation (Physical to Virtual – P2V).
The many backup features of the MC365 include:
- Back up all of your virtual and physical machines with disk-level snapshots including operating system, applications, and data.
- Compression and deduplication optimize utilization of the network and storage. The volume of backup data can be reduced by up to 90% and maximizes backup speed.
- Manage the backup operations of all of your physical and virtual machines from a single centralized backup management console.
- Capability to create sector-by-sector backups for an exact copy of your disk or volume including unused space.
- Granular and file-level backups allow you to selectively back up specific files and folders, or even network shares.
- Manually exclude non-essential files or folders from your backups.
- Flexible scheduling options including hourly, daily, weekly, event-based backups and wake-on-LAN support.
- Manual or scheduled automatic backup validation.
- Balance all backups with bandwidth and disk-write speed throttling.
- SSL-encrypted data transmissions over the network and 256-bit AES encryption of backups protect your data.
- Change Block Tracking (CBT) of Virtual Machine backups reduces the volume of the backup data.
- Virtual Application (vApp) support to capture and recover entire vApps and their configurations.
- Pre/post commands.
- Remote installation and configuration of agents and updates across physical servers as well asremote restore.
- Perform agentless backups on all Virtual Machines running on MC365, VMware, and Hyper-V appliances.
- No additional licenses required to back up any Virtual Machines running on the MC365 including Exchange, SQL, SharePoint and Active Directory VMs.
- Migrate your physical servers into virtual servers that are hosted on the MC365. Spin up new VMs as needed.
- Synchronously replicate an entire MC365 to a second on premises MC365 for extra data protection and business continuity.
- For optimal disaster recovery, asynchronously replicate your Virtual Machines, backups, and data storage to a MC365 appliance at a remote site or in the cloud.
Optional Super Scale Out Across Multiple MC365 Nodes
All MC365 appliances can be scaled up to 256 drives per node to achieve up to 1.5 PetaBytes of raw storage capacity for your storage and backups.
However, StoneFly’s optional Super Scale Out Storage upgrade allows the MC365 to be scaled out to a nearly unlimited storage capacity while increasing performance across multiple nodes for aggregation of throughput. The Backup Controller can be run on a single node or across all of the MC365 nodes.
Adding Super Scale Out Storage to the MC365 enables it to deliver unprecedented performance, redundancy and scalability. MC365 appliances with StoneFly’s Super Scale Out were designed for customers requiring a powerful storage solution that can scale out storage capacity while scaling up performance. Perfect for managing large quantities of backups and unstructured (file-based) data within a single global namespace and a single file system. StoneFly’s Super Scale Out was designed for markets that require vast quantities of high bandwidth throughput or fast parallel throughput for very large files required by high performance computing in media and entertainment.
MC365 appliances with StoneFly’s Super Scale Out feature allows you to “scale out” as your business grows by adding nodes without losing performance. You can expand one or more volumes across multiple nodes using no metadata and a single namespace. Usable bandwidth increases as new nodes are added. Best of all, you can manage multiple nodes with just a single user interface. Each time MC365 nodes are scaled out, it adds more capacity, more throughput, and more concurrency. Installation, management and scaling is simple to achieve at any size.
Additional MC365 nodes can be added on the fly while adding CPU horsepower and storage capacity. This linear scalability provides predictable performance and allows users to pay as you grow and to only buy what you need.
What is Super Scale Out Storage?
Super Scale Out Storage is a distributed file system that can scale to several petabytes all while handling thousands of clients. It functions as a distributed data overlay, polling together storage building blocks over TCP/IP, aggregating disk resources and managing data in a single global namespace. The unified platform handles blocks, files, objects and big data.
Super Scale Out solves enterprise storage requirements, including:
- Backup target and archive for on-site or off-site data protection.
- Enterprise-wide file sharing with a single access point across data storage locations.
- Nearline storage for infrequently accessed data that needs to be online.
- Rich media (audio and video) content distribution with petabyte-scale storage and high-read performance requirements.
- High-performance storage for bandwidth-intensive applications .
- Centralized storage-as-a-service to enterprise applications.
For additional performance and twice the redundancy, MC365 with Super Scale Out can also be configured as mirrored twin appliance nodes using a single name space volume. The Backup Controller can be run on a single set of twin nodes or across all of the MC365 twin nodes.